Khái niệm RAG là gì? Cơ chế Retrieval – Augmented Generation, lợi ích và ứng dụng thực tế
Trong bối cảnh trí tuệ nhân tạo (AI) bùng nổ, các mô hình ngôn ngữ lớn (LLMs) như GPT, Llama, Claude… ngày càng được ứng dụng mạnh mẽ. Tuy nhiên, chúng vẫn có hạn chế cố hữu: không có khả năng truy xuất dữ liệu mới theo thời gian thực, dẫn đến hiện tượng “ảo giác” (hallucination). Cùng tìm hiểu Khái niệm, lợi ích và ứng dụng của RAG.
Để khắc phục điều này, RAG – Retrieval-Augmented Generation ra đời và trở thành nền tảng quan trọng trong các hệ thống AI hiện đại.
1. Khái niệm RAG là gì?
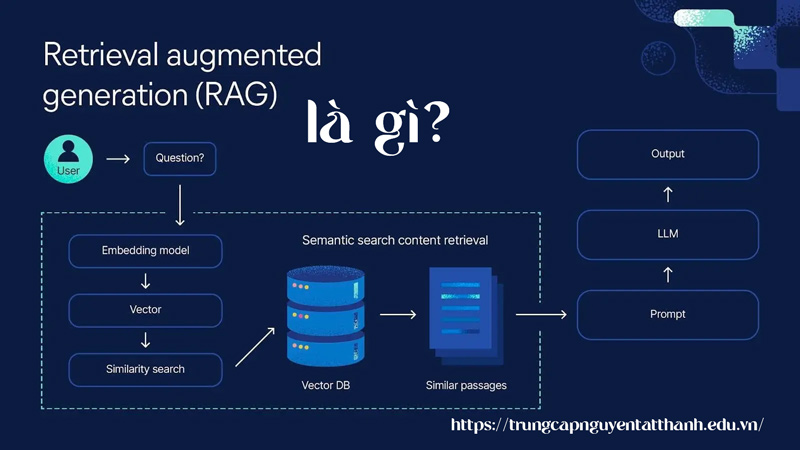
RAG (Retrieval – Augmented Generation) là kỹ thuật kết hợp giữa:
-
Retrieval: Truy xuất dữ liệu từ nguồn bên ngoài (database, tài liệu PDF, website, knowledge base…)
-
Generation: Sinh câu trả lời bằng mô hình ngôn ngữ lớn (LLM)
Tức là trước khi AI tạo ra câu trả lời, hệ thống sẽ tìm kiếm các thông tin liên quan, sau đó đưa dữ liệu đó vào mô hình để sinh nội dung chính xác và cập nhật hơn.
Hay nói đơn giản:
RAG = AI sinh văn bản + truy xuất dữ liệu ngoài giúp trả lời đúng, hạn chế ảo giác.
Bài viết liên quan: Chat AI là gì? Tìm hiểu về trí tuệ nhân tạo hội thoại và ứng dụng thực tế
2. Cơ chế hoạt động của Retrieval-Augmented Generation
RAG hoạt động qua 4 bước chính:
Bước 1: Chuẩn hóa & chia nhỏ dữ liệu (Preprocessing)
Tài liệu được phân chia thành các đoạn nhỏ (chunks) và chuyển thành vector embeddings.
Bước 2: Lưu trữ vào Vector Database
Những embeddings này được lưu vào một cơ sở dữ liệu dạng vector (VD: Pinecone, ChromaDB, Weaviate).
Bước 3: Truy xuất thông tin liên quan (Retrieval)
Khi người dùng đặt câu hỏi:
→ Hệ thống chuyển câu hỏi thành vector
→ Tìm những đoạn tài liệu giống nhất trong vector database
→ Trả về các đoạn văn có liên quan nhất
Bước 4: Tạo câu trả lời (Generation)
Các đoạn dữ liệu được ghép thành “context”, gửi vào mô hình LLM để sinh câu trả lời dựa trên dữ liệu thực, thay vì đoán mò.

3. Khái niệm lợi ích và ứng dụng của RAG
>> Lợi ích của RAG
✔ Tăng độ chính xác
RAG sử dụng dữ liệu thực tế → giảm sai sót và giảm hiện tượng ảo giác của AI.
✔ Thông tin luôn cập nhật
LLM không cần đào tạo lại nhưng vẫn có thể
trả lời bằng dữ liệu mới nhất, chỉ cần cập nhật vào database.
✔ Chi phí thấp hơn fine-tuning
Không phải huấn luyện lại mô hình lớn → tiết kiệm chi phí GPU.
✔ Bảo mật dữ liệu doanh nghiệp
Tài liệu nội bộ được lưu trữ riêng → AI chỉ truy xuất dữ liệu của công ty.
✔ Giải thích được (Explainability)
Có thể hiển thị “nguồn tham khảo” từ tài liệu truy xuất.
4. Ứng dụng thực tế của RAG
- Chatbot chăm sóc khách hàng
Truy xuất nội dung từ: FAQ, tài liệu hướng dẫn, chính sách → trả lời đúng 95–98%.
- Trợ lý nội bộ doanh nghiệp
Truy xuất tài liệu kỹ thuật, quy trình, hồ sơ → nhân viên tra cứu nhanh hơn 10 lần.
- Tóm tắt và phân tích tài liệu dài
PDF, Word, văn bản pháp luật… → AI tóm tắt theo đúng nội dung gốc.
- Công cụ tra cứu y tế – giáo dục – pháp lý
Thông tin cần độ chính xác cao, cập nhật liên tục.
- Hệ thống tìm kiếm thông minh (AI Search)
Tìm kiếm theo ý nghĩa (semantic search), không chỉ dựa từ khóa.
- Tự động hóa quy trình làm việc
Hỗ trợ xử lý email, báo cáo, hợp đồng dựa trên dữ liệu có thật.
5. Ưu điểm và nhược điểm của RAG
+ Ưu điểm của RAG
➤ Giảm ảo giác của mô hình AI
RAG cho phép mô hình truy xuất dữ liệu thực tế trước khi trả lời, giúp hạn chế tình trạng AI tự bịa (hallucination) – một trong những vấn đề lớn của các LLM.
➤ Trả lời dựa trên dữ liệu mới nhất
Không giống như mô hình truyền thống chỉ biết thông tin đến thời điểm huấn luyện, RAG có thể dùng dữ liệu được cập nhật liên tục trong vector database.
→ Giúp AI luôn “hiện đại hóa” thông tin.
➤ Không cần fine-tuning tốn kém
Bạn không phải huấn luyện lại mô hình lớn, chỉ cần thêm dữ liệu mới vào DB.
→ Tiết kiệm chi phí, thời gian, tài nguyên GPU.
➤ Bảo mật và phù hợp cho doanh nghiệp
Dữ liệu nội bộ như: quy trình, SOP, tài liệu kỹ thuật, báo cáo… được lưu trong hệ thống riêng → AI chỉ truy xuất trong phạm vi dữ liệu doanh nghiệp cung cấp.
→ Đảm bảo bảo mật và kiểm soát thông tin.
➤ Khả năng mở rộng linh hoạt
Chỉ cần mở rộng kho dữ liệu hoặc thay đổi loại vector DB, hệ thống vẫn chạy ổn định.
→ RAG phù hợp với doanh nghiệp lớn và hệ thống nhiều dữ liệu.
➤ Dễ bảo trì và nâng cấp
Khi có dữ liệu mới: chỉ việc tải tài liệu lên và để hệ thống embedding + lưu vào DB.
Không cần đào tạo lại mô hình từ đầu.
➤ Tính giải thích cao (Explainability)
RAG có thể hiển thị nguồn tham chiếu (citations), giúp người dùng kiểm chứng:
-
đoạn nào được lấy từ tài liệu nào
-
tại sao AI trả lời như vậy
Điều này quan trọng trong ngành y tế, pháp lý, ngân hàng.
+ Nhược điểm của RAG
Mặc dù mạnh mẽ, RAG cũng tồn tại một số thách thức:
➤ Phụ thuộc vào chất lượng dữ liệu gốc
Nếu dữ liệu đầu vào:
-
không sạch
-
không đủ thông tin
-
không được phân chia hợp lý
→ Kết quả truy xuất sẽ kém chính xác → LLM trả lời sai theo dữ liệu xấu.
➤ Truy xuất sai dẫn đến câu trả lời sai
RAG chỉ tốt khi retriever tìm đúng đoạn dữ liệu. Nếu tìm sai:
→ LLM sinh trả lời dựa trên thông tin không liên quan.
Hiện tượng này gọi là Garbage In – Garbage Out.
➤ Yêu cầu kỹ thuật phức tạp
Triển khai RAG cần nhiều thành phần:
-
Vector database
-
Embedding model
-
LLM
-
Pipeline truy xuất
-
Chunking & indexing
-
Tối ưu RAG (reranking, caching…)
Doanh nghiệp nhỏ có thể gặp khó khăn khi tự triển khai.
➤ Tốn tài nguyên khi tài liệu quá lớn
Khi kho dữ liệu lên đến hàng triệu tài liệu, vector DB cần:
-
dung lượng lưu trữ lớn
-
RAM mạnh
-
hạ tầng tối ưu
Nếu không → tốc độ truy xuất chậm.
➤ Tối ưu chunk size đòi hỏi kinh nghiệm
-
Chunk quá nhỏ → thiếu ngữ cảnh
-
Chunk quá lớn → nặng, gây tốn token, AI khó xử lý
Việc chọn kích thước chunk phù hợp là một thách thức kỹ thuật.
➤ Không phải lúc nào cũng thay thế được fine-tuning
RAG phù hợp khi câu trả lời phụ thuộc vào dữ liệu cụ thể.
Nhưng nếu doanh nghiệp cần AI:
-
nói theo phong cách riêng
-
xử lý tác vụ đòi hỏi suy luận sâu
-
hiểu chuyên ngành đặc biệt
→ Fine-tuning vẫn cần thiết.
➤ Có độ trễ (latency) cao hơn
Quy trình RAG gồm nhiều bước:
Truy xuất → Rerank → Kết hợp → Sinh trả lời
→ Thời gian phản hồi chậm hơn so với mô hình trả lời trực tiếp.
Bạn nên dùng RAG nếu:
-
Dữ liệu thay đổi thường xuyên
-
Cần độ chính xác cao
-
Không muốn tốn chi phí huấn luyện lại mô hình
-
Cần AI trả lời dựa trên tài liệu nội bộ
-
Tài liệu lớn, dài và khó tìm kiếm

6. Khi nào nên dùng RAG?
Bạn nên dùng RAG nếu:
-
Dữ liệu thay đổi thường xuyên
-
Cần độ chính xác cao
-
Không muốn tốn chi phí huấn luyện lại mô hình
-
Cần AI trả lời dựa trên tài liệu nội bộ
-
Tài liệu lớn, dài và khó tìm kiếm
7. RAG và Fine-tuning – khác nhau thế nào?
| Tiêu chí | RAG | Fine-tuning |
|---|---|---|
| Cập nhật dữ liệu | Dễ dàng | Khó, tốn chi phí |
| Độ chính xác nội dung | Cao | Tùy chất lượng dữ liệu |
| Chi phí | Rẻ | Đắt |
| Khả năng mở rộng | Rất tốt | Hạn chế |
| Tình huống dùng | Trả lời dựa trên tài liệu cụ thể | Thay đổi phong cách, chuyên môn mô hình |
Như vậy thông thường, doanh nghiệp kết hợp RAG + Fine-tuning để đạt hiệu quả tối đa.
Kết luận
RAG là bước tiến quan trọng của AI, giúp mô hình ngôn ngữ trả lời chính xác hơn, cập nhật hơn và phù hợp cho nhu cầu doanh nghiệp. Với cơ chế truy xuất dữ liệu + sinh nội dung, RAG mở ra hàng loạt ứng dụng mạnh mẽ trong chăm sóc khách hàng, giáo dục, y tế, pháp lý, và tự động hóa doanh nghiệp.