Từ Model-Centric Sang Data-Centric: Tại Sao Dữ Liệu Sạch Là “Vua” Trong Kỷ Nguyên AI 2026?
Trong suốt thập kỷ qua, cộng đồng trí tuệ nhân tạo (AI) toàn cầu đã đổ dồn sự chú ý vào việc xây dựng những mô hình khổng lồ với hàng tỷ tham số. Tuy nhiên, năm 2026 đánh dấu một bước chuyển mình mạnh mẽ: Tư duy lấy dữ liệu làm trung tâm (Data-Centric AI).
Bài viết này sẽ phân tích sâu lý do tại sao chất lượng dữ liệu hiện nay mới là yếu tố quyết định sự sống còn của một dự án AI.

Tổng quan về Data-Centric AI
Data-Centric AI là một phương pháp tiếp cận trong lĩnh vực trí tuệ nhân tạo, nơi trọng tâm công việc được chuyển dịch từ việc cải thiện mã nguồn thuật toán sang việc nâng cao chất lượng dữ liệu.
Thay vì giữ nguyên dữ liệu và liên tục tinh chỉnh mô hình (Model-Centric), phương pháp này giữ cố định kiến trúc mô hình và tập trung vào việc làm sạch, chuẩn hóa và dán nhãn dữ liệu một cách chính xác nhất.
> Bài viết liên quan: Chương trình đào tạo trí tuệ nhân tạo (AI)
Các đặc điểm chính của Data-Centric AI:
-
Ưu tiên chất lượng hơn số lượng: Thay vì nạp vào hàng tỷ dữ liệu “nhiễu”, phương pháp này tập trung vào những bộ dữ liệu nhỏ nhưng có độ chính xác và tính nhất quán cao.
-
Nhất quán trong dán nhãn: Đảm bảo các nhãn dữ liệu được gán một cách đồng bộ, loại bỏ sự mơ hồ giúp mô hình học tập hiệu quả hơn.
-
Giải quyết lỗi từ gốc: Khi mô hình hoạt động không tốt, kỹ sư sẽ phân tích dữ liệu để tìm ra các điểm sai lệch (bias) hoặc thiếu sót thay vì chỉ thay đổi tham số mô hình.
Tại sao nó quan trọng?
-
Tiết kiệm tài nguyên: Giúp những mô hình nhỏ hơn đạt được hiệu suất cao tương đương với các mô hình khổng lồ, từ đó giảm chi phí hạ tầng và năng lượng.
-
Tăng độ tin cậy: Giúp giảm thiểu các lỗi do “dữ liệu rác” gây ra, giúp AI đưa ra các quyết định chính xác và công bằng hơn trong thực tế.
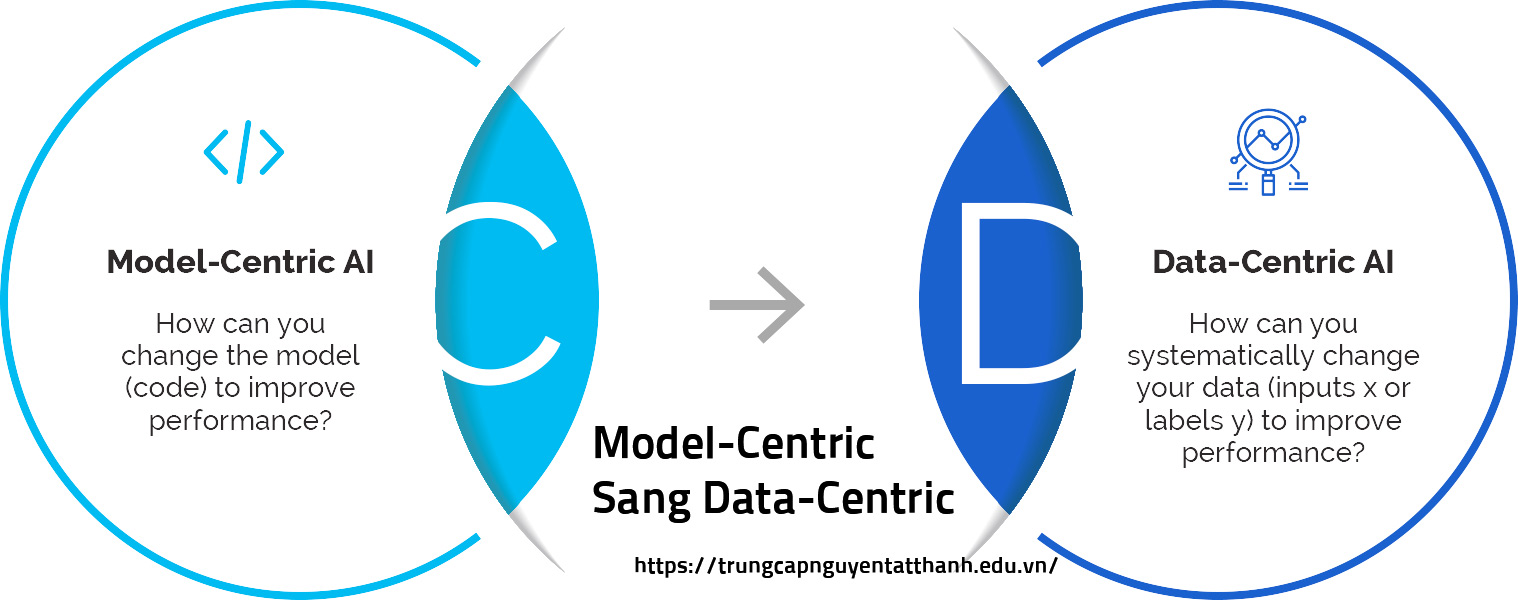
1. Hiểu đúng về Model-Centric và Data-Centric
Để hiểu tại sao có sự chuyển dịch này, chúng ta cần đặt hai khái niệm lên bàn cân so sánh:
1.1. Cách tiếp cận Model-Centric (Lấy mô hình làm trung tâm)
Đây là phương pháp truyền thống. Khi kết quả của AI không tốt, các kỹ sư thường giữ nguyên bộ dữ liệu và cố gắng:
-
Thay đổi kiến trúc mạng nơ-ron (từ CNN sang Transformer, v.v.).
-
Tinh chỉnh các siêu tham số (Hyperparameters).
-
Tìm kiếm các thuật toán tối ưu hóa mới.
1.2. Cách tiếp cận Data-Centric (Lấy dữ liệu làm trung tâm)
Ngược lại, Data-Centric AI giữ cho mô hình ổn định và tập trung nguồn lực vào việc:
-
Loại bỏ các nhãn dán sai (mislabeling).
-
Xử lý các dữ liệu bị nhiễu hoặc không nhất quán.
-
Bổ sung dữ liệu cho các trường hợp thiếu hụt (Data Augmentation).
2. Tại sao Dữ liệu sạch lại trở thành “Vua”?
2.1. Quy luật “Garbage In – Garbage Out” (Đầu vào là rác, đầu ra là rác)
Dù bạn sở hữu một siêu máy tính hay một mô hình AI tiên tiến nhất thế giới, nếu bạn nạp vào đó dữ liệu sai lệch, kết quả trả về sẽ hoàn toàn vô trị. Dữ liệu sạch giúp mô hình nắm bắt đúng bản chất vấn đề thay vì học những sai số ngẫu nhiên.
2.2. Hiệu quả về chi phí và tài nguyên
Việc huấn luyện (train) các mô hình cực lớn tiêu tốn hàng triệu USD tiền điện và hạ tầng phần cứng. Thay vì cố gắng xây dựng một mô hình lớn hơn để bù đắp cho dữ liệu kém, việc làm sạch dữ liệu giúp những mô hình nhỏ hơn, gọn nhẹ hơn đạt được độ chính xác tương đương hoặc cao hơn. Điều này đặc biệt quan trọng đối với các doanh nghiệp vừa và nhỏ.
2.3. Giải quyết bài toán “Thiên kiến” (Bias) trong AI
AI thường phản ánh những định kiến có sẵn trong dữ liệu. Nếu dữ liệu không được làm sạch và chọn lọc kỹ lưỡng, AI có thể đưa ra những quyết định phân biệt đối xử. Tư duy Data-Centric buộc người làm nghề phải kiểm soát chặt chẽ tính công bằng và đa dạng của dữ liệu đầu vào.
3. Quy trình 5 bước xây dựng chiến lược Data-Centric AI chuyên nghiệp
Để áp dụng tư duy này vào thực tế, các chuyên gia tại Gương Kính Sài Gòn gợi ý quy trình sau:
-
Thu thập dữ liệu đa nguồn: Không chỉ số lượng, hãy ưu tiên sự đa dạng của tình huống thực tế.
-
Làm sạch dữ liệu (Data Cleaning): Loại bỏ trùng lặp, xử lý các giá trị trống (NaN) và lọc nhiễu.
-
Dán nhãn nhất quán (Label Consistency): Đảm bảo các chuyên gia dán nhãn dữ liệu có cùng một tiêu chuẩn đánh giá.
-
Phân tích lỗi (Error Analysis): Khi mô hình sai, hãy lật lại tập dữ liệu để xem tại sao nó sai, thay vì vội vàng thay đổi code.
-
Cải thiện dữ liệu lặp đi lặp lại: Đây là một chu kỳ liên tục để mô hình ngày càng thông minh hơn.
4. Kết luận: Tương lai thuộc về những người làm chủ dữ liệu
Nghề AI năm 2026 không còn là cuộc đua của những dòng code phức tạp, mà là cuộc đua của sự tỉ mỉ trong việc thấu hiểu và xử lý dữ liệu. Một bộ dữ liệu sạch, chất lượng cao chính là tài sản quý giá nhất của bất kỳ doanh nghiệp công nghệ nào.